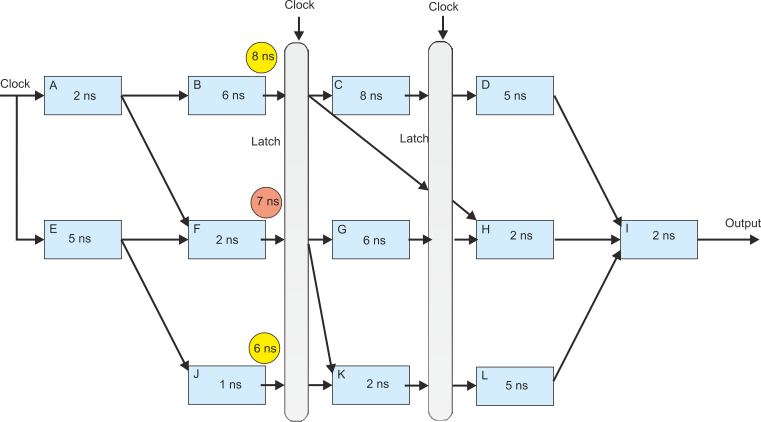
Adding Latches to Implement Pipelining
First, we have to find the delay of the longest block. This is 8 ns. We can’t achieve a flow through of better than one operation per 8 ns.
Suppose we place latches at the outputs of blocks B, F, and J. If we wait 8 ns after the initial clock pulse, the outputs of B, F and J will all be valid (the longest delay path is from F and that is 7 ns). After 8 ns the three inputs are captured and presented to blocks C, G, K and to the next latch.
After another 8 ns the latches are clocked. Now the valid inputs from blocks C, G, K and B are captured in the second latch.
Finally, the second latch provides inputs to blocks D, H and L. After another 7 ns the correct output will appear. A new output will appear every 8 ns after that.
The initial value appears after 24 ns (assuming an output latch) and successive new values every 8 ns after that. The original unpipelined system produces an initial value sooner at 23 ns and then at successive intervals of 23 ns.